Свойства ассоциативности и коммутативности могут быть важной метаинформацией об операторах для среды в которой производятся вычисления.
Классическое определение ассоциативности и коммутативности задано для бинарных операторов. Оператор $f$ является ассоциативным, если \[ (A~f~B)~f~C = A~f~(B~f~C), \] и коммутативным, если \[ A~f~B = B~f~A. \] Однако при анализе кода программ этого определения будет недостаточно, так как арность оператора, то есть количество его операндов, может быть любым. Поэтому далее мы перейдём к префиксной нотации, позволяющей работать с произвольной арностью, а также из дополнительных соображений воспользуемся записью в S-выражениях. Исходные определения в новой записи выглядят следующим образом: \[ (f~(f~A~B)~C) = (f~A~(f~B~C)),\\ (f~A~B) = (f~B~A). \]
Наличие свойств ассоциативности и коммутативности можно рассматривать как бинарый и унарный предикаты: (A-p x y) и (K-p x). В классическом примере оператор является "самоассоциативным", так как (A-p f f) = true, но ничто не мешает подставить два разных оператора и далее мы увидим, что в этом есть смысл.
Практически всегда при компилиции или интерпритации кода появляется промежуточная форма $-$ абстрактное синтаксическое дерево. Представление кода в виде данных используется в качестве единого интерфейса между частями компиляторов или интерпритаторов, позволяя разделить этапы разбора, анализа и трансформации. На основе этого представления мы установим связь между допустимыми преобразованиями выражений и свойствами ассоциативности и коммутативности. Так как S-выражение есть представление дерева, абстрактное синтаксическое дерево выражения и само выражение в нашем случае это одно и тоже.
Для удобства работы с выражением и формализации операции поворота введём ещё одно представление, две последовательности. Первой будет последовательность, в которой вычисляются операторы в выражении $F = \{f_1, f_2, \ldots, f_n | f_i < f_j, i<j\}$, вторая $-$ последовательностью, в которой встречаются операнды выражения слева направо $X = \{x_1, x_2, \ldots x_n | x_i < x_j, i<j\}$. Например, для выражения $\mbox{(* a (+ b c))}$ последовательность $F={*,+}$ и $X = {a, b, c}$, а для $\mbox{(+ (* a c) b)}$ $F={+, *}$ и $X={a, c, b}$.
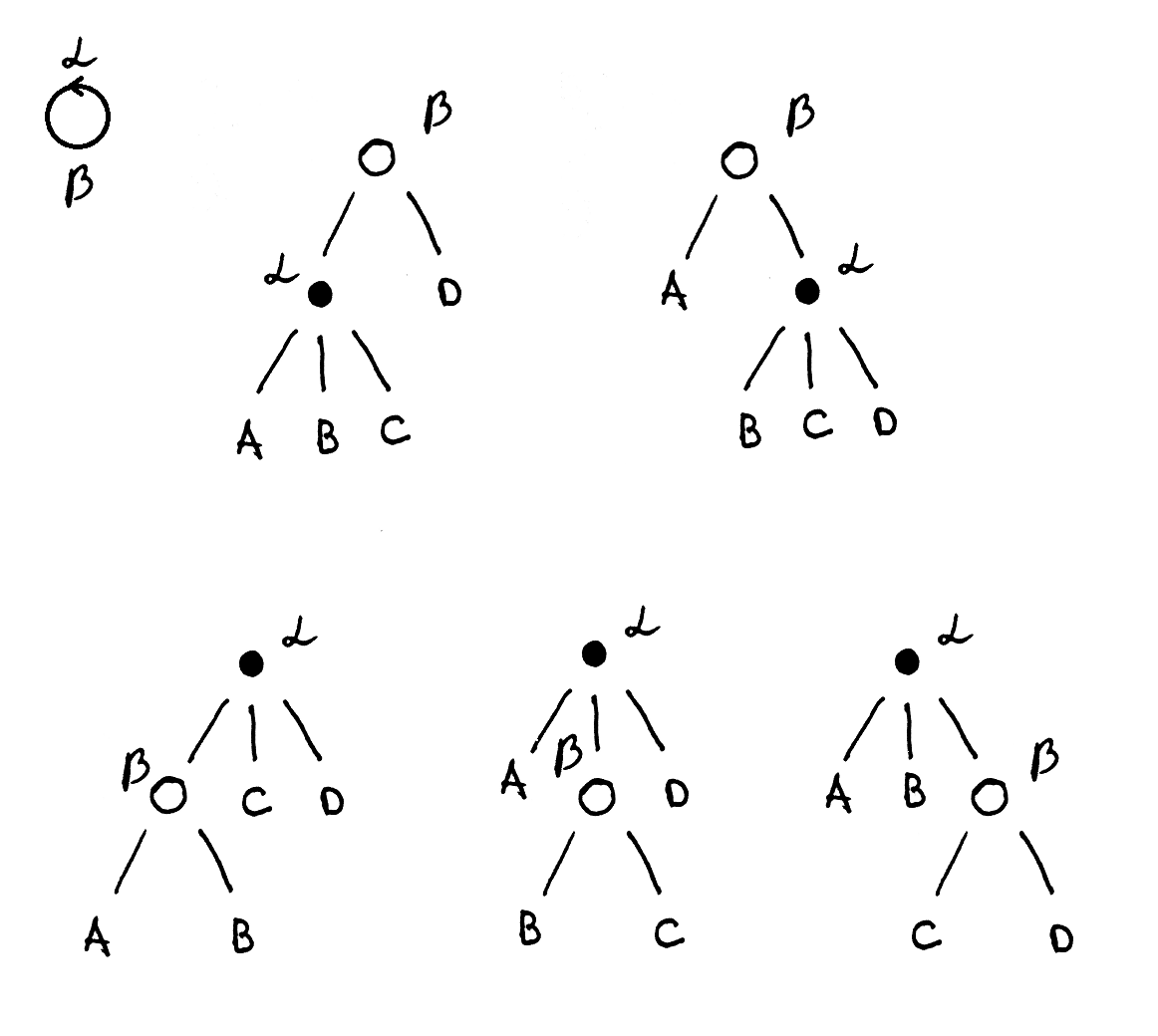
Определим поворот против часовой стрелки. Оператор поворота против часовой стрелки $rotate$ для выражения $S$ вокруг связи между двумя узлами $\alpha$ и $\beta$ с арностями (количеством потомков) $n$ и $k$ описывается двумя случаями. В первом случае дочерний узел не является крайним правым операндом, и поэтому просто сдвигается вправо, становится следующим по очереди слева операндом родительского узла: \[ (\alpha~x_{left}~(\beta~x_i~...~x_{i+k})~x_{right}) \rightarrow (\alpha~x_{left}~(\beta~x_{i+1}~...~x_{i+1+k})_{i+1} x_{right})\\ x_{left} = \emptyset \vee x_{left} \in X, x_{right} \neq \emptyset. \] Во втором случае дочерний узел является крайним правым операндом и тогда меняется порядок следования $\alpha$ и $\beta$. Место первого операнда бывшего дочернего узла $\beta$ теперь занимает $\alpha$, а сам первый операнд $\beta$ занимает место последнего операнда $\alpha$: \[ (\alpha~x_{left}~(\beta~x_i~...~x_{i+k})_i) \rightarrow (\beta~(\alpha~x_{left}~x_i)~x_{i+1}~...~x_{i+k})\\ x_{left} = \emptyset \vee x_{left} \in X. \] Важно, что в обоих случая сохранятся порядок последовательности X.
Для поворота по часовой стрелки первый случай будет идентичен, за исключением того, что вместо прибавления единицы к индексу позиции дочернего узла, мы отнимаем её, а сам узел не должен быть крайним левым операндом. Второй случай для противоположного направления становится зеркальным: \[ (\alpha~(\beta~x_1~...~x_{i+k})_1~x_{right}) \rightarrow (\beta~x_{1}~...~x_{i+k-1}~(\alpha~x_{i+k}~x_{right}))\\ x_{right} = \emptyset \vee x_{right} \in X. \] Достаточно естественно можно получить операторы, применяющие $n$ поворотов против часовой стрелки записав их как $rotate^n$ и по часовой как $rotate^{-n}$.
Так вот, при работе с деревом выражения $S$ ассоциативность двух операторов $\alpha$ и $\beta$ разрешает совершать повороты $(rotate~\alpha~\beta~S)$.
На конкретном выражении нагляднее видно, что происходит при применении поворота. Допустим у нас есть два оператора $\alpha$ и $\beta$ с арностями 3 и 2 соответственно. Количество разных деревьев, получаемых поворотами в одну сторону из исходного равно 5, то есть сумме арностей.
В префиксной записи (S-выражения) деревья выглядят так: \[ (\beta~(\alpha~A~B~C)~D) \rightarrow (\beta~A~(\alpha~B~C~D)) \rightarrow \\ (\alpha~(\beta~A~B)~C~D) \rightarrow (\alpha~A~(\beta~B~C)~D) \rightarrow (\alpha~A~B~(\beta~C~D)). \] Последовательность аргументов в выражении не меняется (A B C D), то есть не меняется порядок встречи листьев, при обходе дерева. Это значит, что если операторы $\alpha$ и $\beta$ не коммутативны, то это свойство не нарушается ни в одном из полученных деревьев.
Исключение составляет случай, когда один из ассоциативных операторов коммутативен. В этом случае второй оператор также будет "коммутативен", его свойство некоммутативности нарушится. При коммутативности мы можем совершать перестановки операндов оператора, тем самым меняя порядок X. Поэтому если (K-p $\alpha$) $\wedge$ (A-p $\alpha$ $\beta$), то из этого следует, что (K-p $\beta$). Например, несмотря на (K-p $\alpha$) = false, при (K-p $\beta$) = true, можно из выражения $(\alpha~A~(\beta~B~C))$ получить $(\alpha~(\beta~B~C)~A)$: \[ (\alpha~A~(\beta~B~C)) ~-rotate^{-1}~\alpha~\beta\rightarrow(\alpha~(\beta~A~B)~C)-\\ ~swap~\beta~1~2\rightarrow(\alpha~(\beta~B~A)~C) ~-rotate~\alpha~\beta\rightarrow(\alpha~B~(\beta~A~C))-\\ ~swap~\beta~1~2\rightarrow(\alpha~B~(\beta~C~A)) ~-rotate^{-1}~\alpha~\beta\rightarrow(\alpha~(\beta~B~C)~A) \]
Коммутативность разрешает применять бинарный оператор swap к дочерним элементам узла.
Наконец, мы дошли до определения свойств в общем виде. Два оператора $f_1$ и $f_2$ арности $n$ и $k$ являются ассоциативными, если для $\forall i \in \{0, n+k\}$ и состоящем из них выражении $S$ выражения: \[ rotate^{i} f_1 f_2 S \] эквивалентны.
Коммутативным является такой оператор $f$ арности $n$, что для любой перестановки операндов $a = \{x_1, \ldots, x_n\}$ выражения $(f~a)$ эквивалентны. Эквивалентность означает возвращение одинакового результата вычислений.
По умолчанию на последовательность операторов и операндов накладывается отношение порядка, вычисления производятся в соответствии с заданным алгоритмом - стратегией вычисления. В большинстве языков это вызов по значению. Было бы удивительно, если бы MOV EAX, EBX; MOV EBX, ECX; выполнялось в случайном порядке. Но только потому, что MOV не ассоциативный и не коммутативный оператор. Существует большое количество случаев, когда такие ограничения не нужны.
На основе последовательностей операторов F и операндов X мы также можем забабахать следующую полезную таблицу:
| Оператор | Не коммутативен | Коммутативен |
| Не ассоциативен | $f_1 < f_2 < ... < f_m;$ $x_1 < x_2 < ... < x_n;$ |
$f_1 < f_2 < ... < f_m;$ $x_1 = x_2 = ... = x_n;$ |
| Ассоциативен | $f_1 = f_2 = ... = f_m;$ $x_1 < x_2 < ... < x_n;$ | $f_1 = f_2 = ... = f_m;$ $x_1 = x_2 = ... = x_n;$ |
Знаки $<$ и $=$ обозначают отношения порядка: $x_1 = x_2$ - не упорядочены, $x_1 < x_2$ - упорядочены. То есть $x_1$ меньше, чем $x_2$, или $x_1$ предшествует $x_2$.
Ассоциативность и коммутативность снимают ограничения на порядок вычислений. Увеличение хаотичности открывает две возможности: оптимизацию порядка вычисления операторов и возможность параллельных вычислений.
Если оператор не коммутативен и не ассоциативен, то вид исходного выражения единственный для соответствующего результата, а значит выражение будет вычисляться последовательно.
Примером ассоциативного, но не коммутативеного оператора является матричное умножение. Например, выражение A*B*C, можно записать как (* (* A B) C) и (* A (* B C)) и выбор одного из вариантов является решением задачи поиска оптимальной расстановки скобок. Одно из решений описано в книге Кормена и Лейзерсона "Алгоритмы. Построение и анализ.", в котором используется подход динамического программирования.
Посмотрим, какую выгоду может принести оптимальный порядок рассчёта. Подставим вместо A скаляр, вместо B матрицу размерности $N^2$, а вместо C транспонированный вектор размерности $N$. В первом случае (* (* s M) $v^T$) $\rightarrow$ (* M $v^T$) $\rightarrow$ $v^T$ будет произведено $2N^2$ умножений и $N(N-1)$ сложений, а во втором (* s (* M $v^T$)) $\rightarrow$ (* s $v^T$) $\rightarrow$ $v^T$, $N^2 + N$ умножений и $N(N-1)$ сложений. На $N^2-N$ умножений меньше. Для последовательного умножения матриц (* A B C) c размерностями (* 30*35 35*15 15*5) оптимальнее рассчитать сначала (* B C), так как в случае (* (* A B) C)) производится (* 30 35 15) + (* 30 15 5) = 18000 умножений, а в случае (* A (* B C)) только (* 35 15 5) + (* 30 35 5) = 7875.
Код оптимизатора:
Если оператор коммутативный, но не ассоциативный, то мы можем поменять местами операнды оператора. Примером может быть функция нахождения среднего чисел.
Для коммутативного и ассоциативного оператора возможно вычислять операторы и операнды операторов в любом порядке. Грубо говоря есть мешок с операторами, мешок с операндами, достаём любой оператор и n любых операндов и вычисляем.